A year ago I started keeping a spreadsheet of every time a customer or a friend asked ChatGPT or Perplexity a buying question in front of me. The list got long. The pattern was always the same: the person typed the question, scanned the answer, and acted on the three brands the model named. Whatever was in those three brands controlled the rest of the conversation.
That is a new distribution channel. It is also a measurement nightmare. Nobody is going to log into a SaaS dashboard every week to find out whether ChatGPT recommends them. They are going to want the answer in the tool they already use, Slack, a weekly report, their own internal app, and they want it as data, not as a chart somebody else designed.
The problem: AI search data is locked inside chat UIs
AI models now sit on top of a meaningful slice of the buying journey. ChatGPT handles roughly a billion queries a day. Perplexity is the default research tool for an entire generation of analysts. Gemini intercepts the long-tail of informational queries that used to feed your blog. Inside all of these, the question buyers ask sounds like "what is the best X for Y," and the answer cites three brands.
The problem is that nobody built these systems to be measured. ChatGPT does not expose a ranking endpoint. Perplexity does not publish citation logs. Gemini renders answers server-side and only partially appears anywhere you can audit. Every team that wants to know how they show up has had to roll their own scraper, deal with rate limits, deal with prompt drift, and rebuild it every time a model updates.
The work is mechanical and unrewarding. It is also exactly the kind of work a small API can absorb on behalf of everyone who needs it.
What Cite42 does
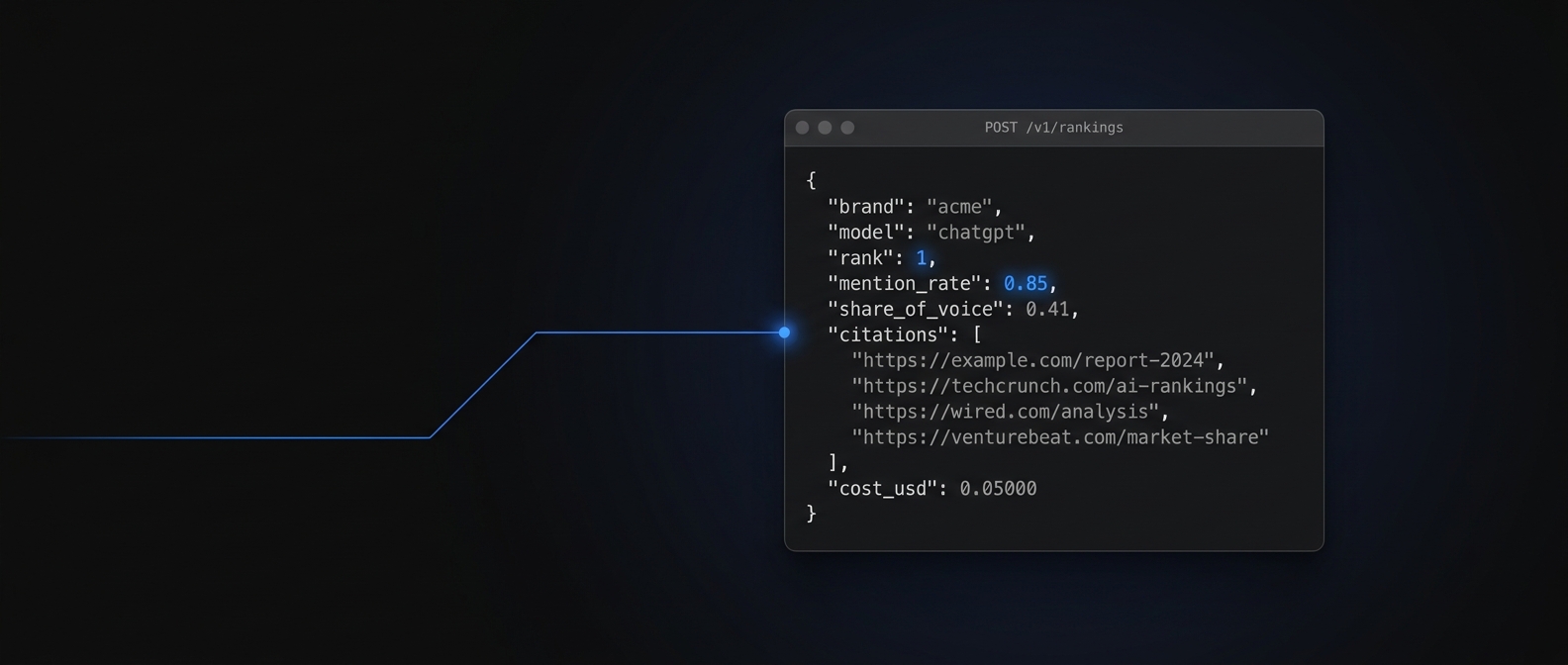
Cite42 exposes one HTTP endpoint per question your team actually asks about AI search. Every endpoint takes the same shape: a prompt set, an optional brand and competitor list, and a list of models. It returns structured JSON.
- Brand rankingsMention rate, average position, and share-of-voice for your brand across ChatGPT, Claude, Perplexity, and Gemini. On-demand or scheduled.
- Citation trackingWhich URLs each model cites for your prompt set, and how often. The first step before you optimise content for AI search inclusion.
- Competitor compareSide-by-side rankings for your brand plus up to 10 competitors, with a co-mention graph, in a single /v1/compare call across all four models.
- Brand sentimentHow each model describes you, positive, neutral, negative, with the exact phrases, in one /v1/sentiment call. Re-run it on a schedule to track tone over time.
- Prompt monitoringThere's no separate monitoring product to buy: cron a /v1/rankings or /v1/compare sweep and diff the runs, or tell your MCP agent to watch a prompt set and ping you when results move. You own the trigger; you pay per call for the data.
Every response includes the raw model output, the parsed structure, and the cost of the call to five decimal places. You can stream the same data into a dashboard, a Slack alert, or your own LLM agent. We do not care which.
Why an API, not a dashboard
There are already three or four well-funded companies selling AI search analytics dashboards. They are fine. They are also the wrong product for everyone we talked to in the first month.
The pattern was consistent. Agencies wanted to embed AI search data inside the reports they already deliver to clients. Founders wanted the data inside their own admin UI so their team could see it without learning another tool. Builders wanted the data inside the agent they were building, so the agent could reason about it. Nobody wanted to log into a fifth dashboard. They wanted the data, and they wanted it as JSON.
That is the bet. The next layer of AI search tooling is not another dashboard. It is the infrastructure that the dashboards, agents, and reports sit on top of. We would rather be the Stripe of AI search than the Mailchimp.
The honest comparison:
| Dashboard product | Cite42 (MCP + API) | |
|---|---|---|
| Surface | Their UI. You log in. | Your UI. You call the endpoint. |
| Pricing model | Seats, monthly minimums, annual contracts | Pay-as-you-go from $25. Credits never expire. |
| Data ownership | Their database. Export sometimes available. | Your codebase. Every call returns full JSON. |
| Best fit | Marketing manager who wants one chart | Builder, agency, or team wiring AI search into their own tooling |
How pricing works
1 USD = 100,000 micro-credits. Every endpoint has a per-call cost, billed to five decimal places, debited from your balance the moment the call returns 2xx. The minimum top-up is $25. Credits never expire.
We picked this model because AI search visibility work is bursty. You run a competitive audit before a quarterly board meeting. You set up weekly prompt monitoring for your three priority queries. You spend $4 in March, $40 in April when you launch a campaign, $1.20 in May. Paying a $99 monthly seat for that workload is absurd. Paying for what you actually call is not.
The full catalogue lives in our pricing page. The short version is that AI-model endpoints bill per model queried, from ~$0.05 per model per call depending on the endpoint, with cached repeats free. The cost of every call is returned in the response so you can budget per request, set per-tenant ceilings, and show your end users what their query is going to cost before they run it.
MCP for Claude Desktop
The same product ships as a Model Context Protocol server. One install command in Claude Desktop, paste your Cite42 API key, and Claude can call the endpoints directly inside a conversation.
The use case that sold us on MCP was a Friday afternoon question. A founder we were working with asked Claude, "has my brand position on ChatGPT changed this week?", and Claude, with the Cite42 MCP installed, called the rankings endpoint, diffed the result against the previous run, and answered in two sentences. No dashboard, no SQL, no Slack alert. Just the question, the answer, and the data in between.
MCP and the REST API share the same credit balance and the same API key. If you call one, you have already integrated the other.
Who this is for, and who it is not
Cite42 is built for builders. Founders wiring AI search into their own admin UI. Agencies embedding the data into client reports. Indie hackers shipping AI-search-adjacent products who want the underlying signal without rebuilding the scraping layer. Internal teams at SaaS companies who want a few hundred calls a month inside their existing dashboard, not another login.
Cite42 is not the right fit if you want a polished dashboard with charts, alerts, and a team seat for every marketer. There are good products that do that, and we will happily tell you which ones. Cite42 exists for the layer underneath those products.
You can grab an API key with $1 free and call any endpoint in the next ten minutes. If the JSON looks like what you want in your codebase, the rest is just a matter of how many calls you make.